“中国要复兴、富强,必须在开源软件领域起到主导作用,为了国家安全和人类发展,责无旁贷,我们须为此而奋斗”——By:云客
资源
Drupal CJK Tokenizer V1.0.0下载
(55.01 KB)
已上传Drupal官网,地址:https://www.drupal.org/project/cjk_tokenizer
中日韩分词器模块
该模块用于为中日韩等语言提供更好更快的搜索体验,对于中日韩等亚洲国家的语言,Drupal的默认实现很简单,
会造成储存浪费、速度缓慢等问题,对于内容较多的站点尤为突出,原因在对这些语言的分词逻辑上,作为改进,
在建立搜索索引时,该模块为这些语言提供自定义分词器,用户可以为每一种语言开启或关闭分词功能,
当开启时可以进一步指定使用哪一个分词器,分词器以插件方式提供,对于中文用户,模块默认提供了百度分词器,
其他语言提供了原Drupal的默认分词器,如不够用,实现一个自定义的分词器仅需提供一个插件即可,这非常简单,
模块已经实现了配置表单、插件调用等基础功能,参照模块已提供的分词器去实现自定义分词器是件很愉快的事情。
中文用户:
模块默认提供了百度分词器,该分词器会调用百度提供的API接口进行分词,因此你需要先到百度申请接口凭据,
地址:http://ai.baidu.com/tech/nlp/lexical
百度的API接口提供50万次的免费请求额度,QPS(每秒查询数)限制为2,对于普通站点通常够用了
如有更高的接口要求,可以联系百度升级,或自定义本地分词器,当百度接口调用失败时,如超限或网络超时,
为能正常使用搜索功能,模块会回退调用原Drupal默认的分词器,可查看日志了解接口调用详情,在必要时,
进行参数调整,如果你需要使用迅搜、结巴、Sphinx等分词器,简单的提供一个插件即可,模块已提供基础设施。
其他语言用户:
模块已经提供了基础设施,如配置表单、插件调用等,如果不想使用Drupal的默认分词器,
那么你需要实现一个自定义分词器,以插件方式提供,开发者请参考代码注释
模块使用:
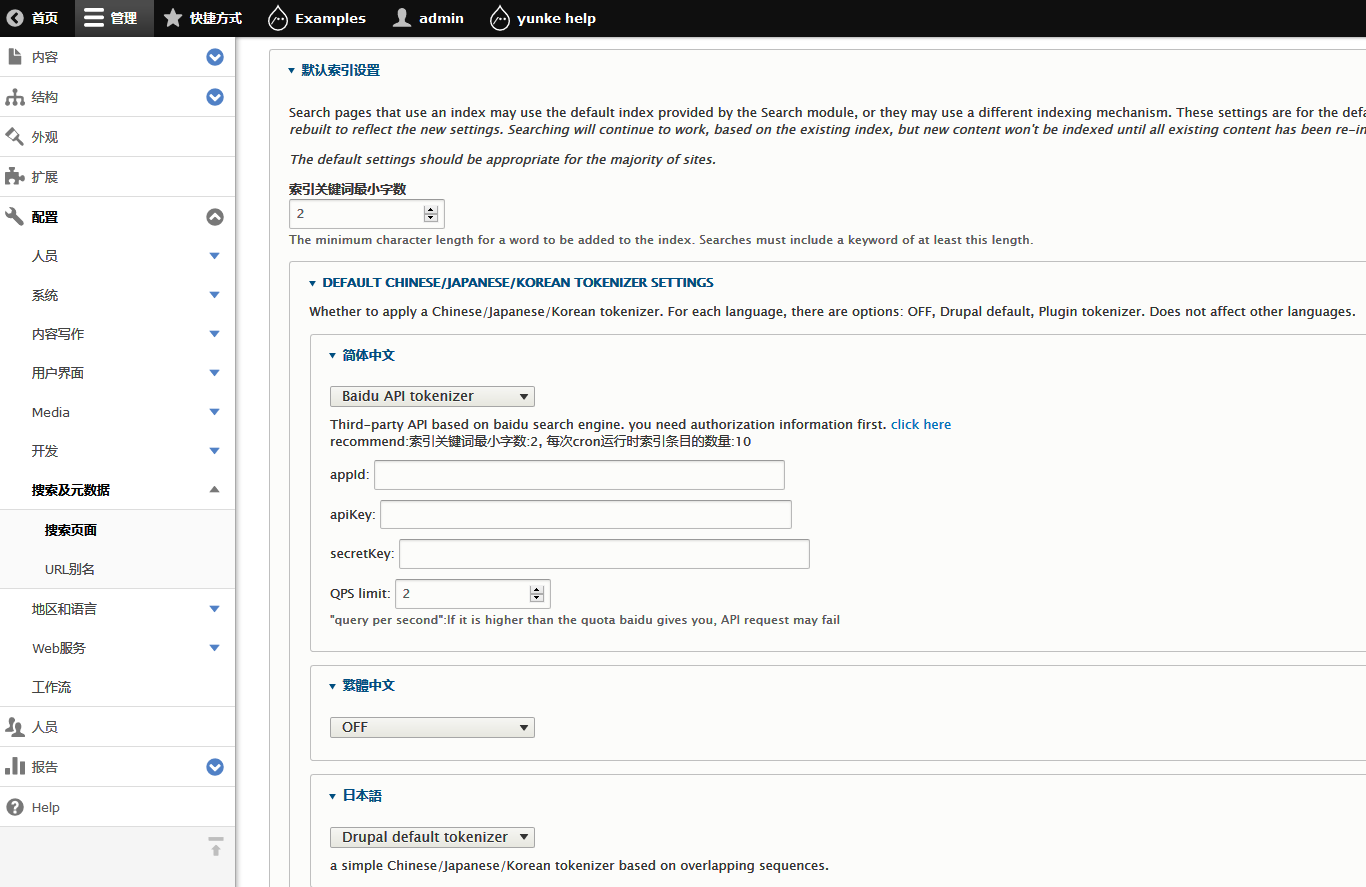
安装本模块后,进入搜索配置页面(/admin/config/search/pages)
为所需语言选择分词器,并进行相关配置,提交成功后,系统将使用本模块进行索引分词
如果你使用百度分词器,请注意:由于该分词器需要通过网络调用API接口,比较耗时,强烈建议将索引条数设置为10,
最小搜索字符数设置为2,并确保服务器能够访问网络,如果有较高的接口QPS可适当提高索引条数
创建索引是在自动任务中静默执行,因此用户将不能直观的感受到本模块的执行,你可以到数据库索引表查看改变
请多留意系统日志,以观察模块运行情况。
卸载模块后原系统默认的CJK分词设置处于关闭状态,请确保开启,否则将无法正常搜索中日韩文内容。
使用反馈:
“水滴间www.indrupal.com” 是本模块的官方网站,请在下载页http://www.indrupal.com/cjk_tokenizer评论区留言
开发者信息:
翻译帮助:
晴空,drupal专业文档网站:“爱码文档汇”第一创始人,地址:http://www.nowicode.com/,《听晴空讲主题》系列文章作者,现居美国
模块开发:
云客【云游天下,做客四方】,《云客drupal源码分析》系列文档作者,个人网站:http://www.indrupal.com,暂居中国深圳

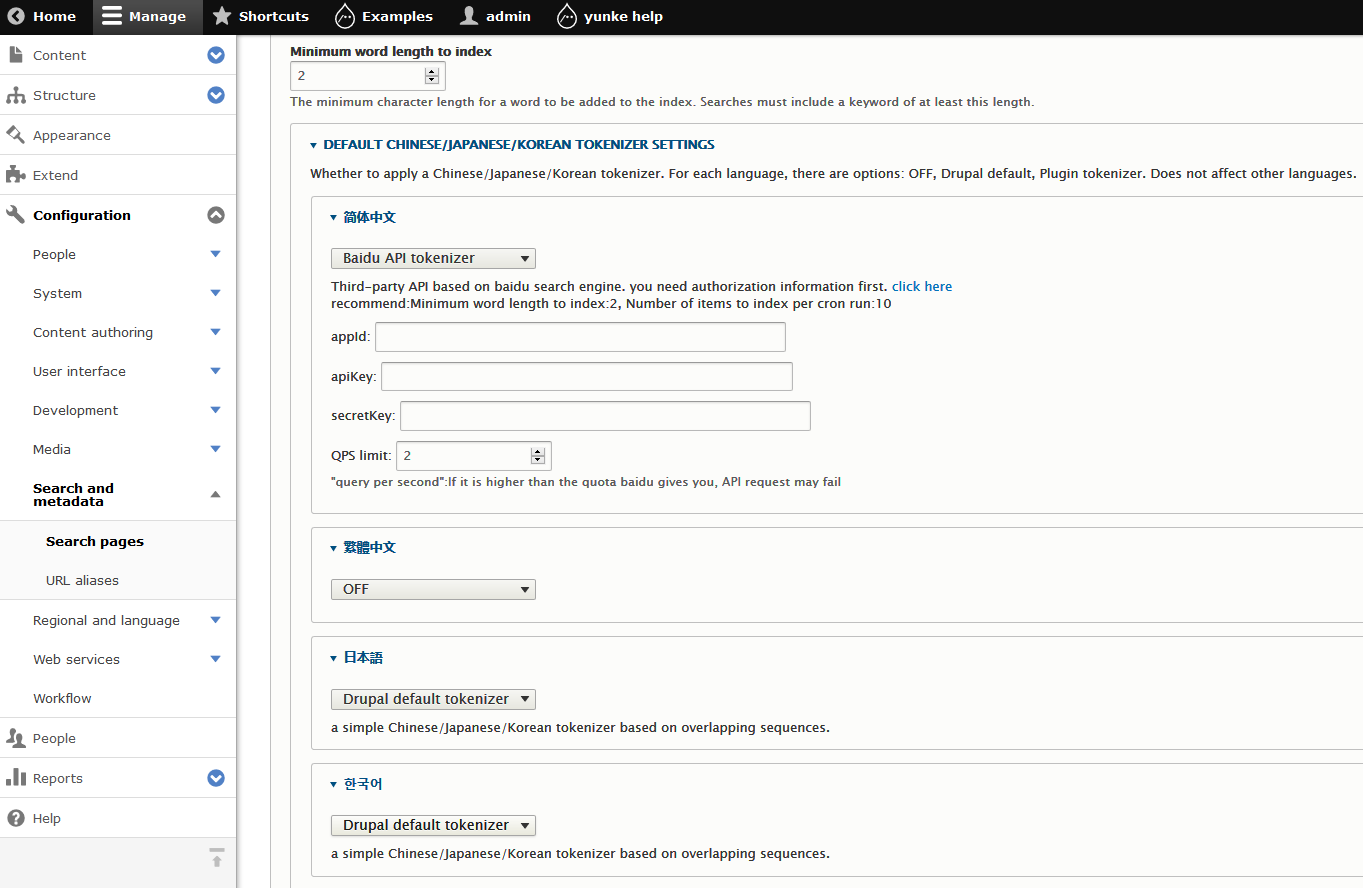
CJK Tokenizer
This module is to provide a better and faster search experience for languages
such as Chinese, Japanese and Korean. For languages in Asia countries, Drupal's default
implementation is too simple, it will cause problems such as waste of storage and slow
down the system. It is especially prominent for sites with a large amount of content. The
reason is that the default words tokenization algorithm is designed to deal with
latin languages like English or German.
As an improvement, When building a search index, this module provides custom words
tokenizer, and let user enable/disable tokenizer for each language. When tokenizer
is enabled, user can further specify which one to use. The tokenizer is provided as a
plug-in. For Chinese users, the module provides Baidu tokenizer by default.
For other languages, there is Drupal's default tokenizer. If this is not enough,
to implement a custom tokenizer only needs to provide a plug-in, which is very simple.
This module has implemented basic functions such as configuration forms and plug-in calls.
For users who do not speak Chinese:
The module already provides infrastructure, such as configuration forms, plugin calls,
etc. If you do not want to use Drupal’s default tokenizer,
you need to implement a custom tokenizer, provided as a plug-in,
developers please refer to the code comments
Developer info:
yunke, lives in Shenzhen, China. Author of "Yunke Drupal 8 Source Code Analysis",
personal website: http://www.indrupal.com
Translator:
Qingkong, lives in USA, Author of "Drupal7 Theme Development" and "Drupal8
Theme Development", both in Chinese. Founder of "NowICode", a Drupal tutorail/doc
website in Chinese. Url: http://www.nowicode.com/
沟通互动